1.Python的内存管理机制
a.内存管理架构

第一层PyMem_API
[pymem.h]
PyAPI_FUNC(void *) PyMem_Malloc(size_t);
PyAPI_FUNC(void *) PyMem_Realloc(void *, size_t);
PyAPI_FUNC(void) PyMem_Free(void *);
[object.h]
void* PyMem_Malloc(size_t nbytes){
return PyMem_MALLOC(nbytes);
}
void* PyMem_Realloc(void *p, size_t nbytes){
return PyMem_REALLOC(p,nbytes);
}
void PyMem_Free(void* p){
PyMem_FREE(p);
}
[pymem.h]
#define PyMem_MALLOC(n) malloc((n) ? (n) : 1)
#define PyMem_REALLOC(n) realloc((p), (n) ? (n) : 1)
#define PyMem_FREE free
[pymem.h]
#define PyMem_New(type,n)
( (type *)PyMem_Malloc((n) * sizeof(type)) )
#define PyMem_NEW(type,n)
( (type *)PyMem_MALLOC((n) * sizeof(type)) )
#define PyMem_Resize(p,type,n)
( (p) = (type *)PyMem_Realloc((p), (n) * sizeof(type)) )
#define PyMem_RESIZE(p,type,n)
( (p) = (type *)PyMem_REALLOC((p), (n) * sizeof(type)) )
#define PyMem_Del PyMem_Free
#define PyMem_DEL PyMem_FREE
第二层构建了PyObject_位前缀的函数族,Pymalloc机制
b.小块空间的内存池
PyObject_Malloc、PyObject_Realloc、PyObject_Free
Block(block 只是一个概念上的东西, 实际不与python某个源码中的东西对应)
[obmalloc.c]
#define ALIGNMENT 8 /* must be 2^N */
#define ALIGNMENT_SHIFT 3
#define ALIGNMENT_MASK (ALIGNMENT - 1)
[obmalloc.c]
#define SMALL_REQUEST_THRESHOLD 256 //block的大小的上限值
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
[obmalloc.c]
//从size class index 转念换到 size class
#define INDEX2SIZE(I) (((uint)(I)+ 1) << ALIGNMENT_SHIFT)
//从size class 转换到 size class size
size = (uint )(nbytes - 1 ) >> ALIGNMENT_SHIFT;
Pool(通常为一个系统内存页)
[obmalloc.c]
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
#define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
[obmalloc.c]
typedef uchar block;
/* Pool for small blocks */
struct pool_header {
union{
block* _padding;
uint count;
} ref; /* number of allocated blocks */
block* freeblock; /* pool's freelist head */
struct pool_header* nextpool; /* next pool of this size class */
struct pool_header* prevpool; /* previous pool */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
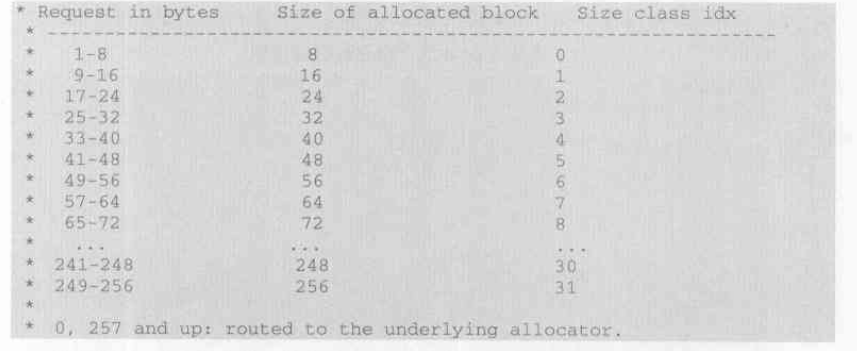
[obmalloc.c]-[convert 4k raw memory to pool]
#define ROUNDUP(x) (((x) + ALIGNMENT_MASK) & ~ALIGNMENT_MASK)
#define POOL_OVERHEAD ROUNDUP(sizeof(struct pool_header))
#define struct pool_header* poolp
#define uchar block
poolp pool;
block* bp;
...// pool指向了一块4KB的内存
pool->ref.count = 1
//设置pool的size class index
pool->szidx = size;
//将size class index转换为size,比如3转换为32字节
size = INDEX2SIZE(size);
//跳过用于pool_header的内存,并进行对齐
bp = (block *)pool + POOL_OVERHEAD
//实际就是pool->nextoffset = POOL_OVERHEAD + size + size
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
return (void *)bp;
//申请内存
[obmalloc.c]-[allocate block]
if(pool != pool->nextpool){
++pool->ref.count;
bp = pool->freeblock;
...
if(pool->nextoffset <= pool->maxnextoffset){
//有足够的block空间
pool->freeblock = (block *)pool + pool->nextoffset;
pool->nextoffset += INDEX2SIZE(size);
*(block **)(pool->freeblock) = NULL;
return (void *)bp;
}
}
[obmalloc.c]
//基于地址P获得离P最近的pool的边界地址
#define POOL_ADDR(P) ((poolp)((uptr)(P) & ~(uptr)POOL_SIZE_MASK))
void PyObject_Free(void* p){
poolp pool;
block* lastfree;
poolp next,prev;
uint size;
pool = POOL_ADDR(p);
//判断p指向的block是否属于pool
if(Py_ADDRESS_IN_RANGE(p,pool)){
*(block **)p = lastfree = pool->freeblock;
pool->freeblock = (block *)p;
...
}
}
/* 遍历是通过freeblock = *freeblock */
[obmalloc.c]-[allocate block]
if(pool != pool->nextpool){
++pool->ref.count;
bp = pool->freeblock;
if((pool->freeblock = *(block **)bp) != NULL){
return (void *bp);
}
if(pool->nextoffset <= pool->maxnextoffset){
....
}
...
}
arena
多个pool聚合的结果就是一个arena,一个arena256KB
[obmalloc.c]
#define ARENA_SIZE (256 << 10) /* 256KB */
[obmalloc.c]
typedef uchar block;
struct arena_object {
uptr address;
block* pool_address;
uint nfreepools;
uint ntotalpools;
struct pool_header* freepools;
struct arena_object* nextarena;
struct arena_object* prevarena;
}
"未使用"的arena和“可用”的arena
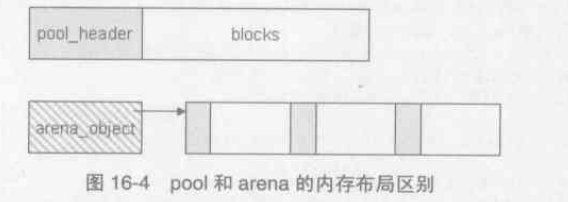
pool_header与arena_object对比:当pool_header被申请时,它所管理的pool集合的内存一定也被申请;但是当arena_object被申请时,它所管理的pool集合的内存则没有被申请
arena的两种状态: 当一个arena的arena_object没有与pool集合建立联系时,这时的arena处于“未使用”状态,一旦建立了联系,这时arena就转换到了“可用”状态。
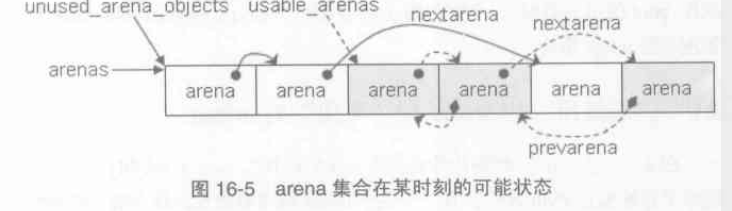
”未使用“的arena的链表表头是unused_arena_objects,通过nextarena链接,是一个单项链表
”可用“的arena的链表表头是usable_arenas,通过nextarena与prevarena链接,是一样个双向链表
申请arena
[obmalloc.c]
//arenas管理着arena_object的集合
static struct arena_object* arenas = NULL;
//当前arenas中管理的arena_object的个数
static uint maxarena = 0;
//”未使用“arena_object链表
static struct arena_object* unused_arena_objects = NULL;
//”可用“arena_object链表
static struct arena_object* usable_arenas = NULL;
//初始化是需要申请的arena_object的个数
#define INITIAL_ARENA_OBJECTS 16;
static struct arena_object* new_arena(void){
struct arena_object* arenaobj;
uint excess; /* number of bytes above pool alignment */
//判断是否需要扩充”未使用“arena_object列表
if(unused_arena_objects == NULL){
uint i;
uint numarenas;
size_t nbytes;
//确定本次需要申请的arena_object的个数,并申请内存
numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
if(numarenas <= maxarenas)
return NULL; //溢出
nbytes = numarenas * sizeof(*arenas);
if(nbytes/sizeof(*arenas) != numarenas)
return NULL; //溢出
arenaobj = (struct arena_object *)realloc(arenas,nbytes);
if(arenaobj == NULL)
return NULL;
arenas = arenaobj;
//初始化新申请的arena_object,并将其放入unused_arena_objects链表中
for(i = maxarenas; i < numarenas; ++i){
arenas[i].address = 0; /* mark as unassocaited */
arenas[i].nextarena = i < numarenas -1 ? &arenas[i+1] : NULL;
}
/* Update globals */
unused_arena_objects = &arenas[maxarenas];
maxarenas = numarenas;
}
//从unused_arena_objects链表中取出一个”未使用“的arena_object
arenaobj = unused_arena_objects;
unused_arena_objects = arenaobj->nextarena;
assert(arenaobj->address == 0);
//申请arena_object管理的内存
arenaobj->address = (uptr)malloc(ARENA_SIZE);
++narenas_currently_allocated;
//设置pool集合的相关信息
arenaobj->freepools = NULL;
arenaobj->pool_address = (block *)arenaobj->address;
arenaobj->nfreepools = ARENA_SIZE/POOL_SIZE;
//将pool的起始地址调整为系统页的边界
excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
if(excess != 0){
--arenaobj->nfreepools;
arenaobj->pool_address += POOL_SIZE - excess;
}
arenaobj->ntotalpools = arenaobj->nfreepools;
return arenaobj;
}
内存池
可用pool缓冲池--usedpools
当Python在WITH_MEMORY_LIMITS编译符号打开的情况下进行编译时,Python的另一个符号会被激活,这个名为SMALL_MEMORY_LIMIT的符号限制了整个内存池的大小,同时也就限制了可以创建的arena的个数
[obmalloc.c]
#ifdef WITH_MEMORY_LIMITS
#ifndef SMALL_MEMORY_LIMIT
#define SMALL_MEMORY_LIMIT (64 * 1024 * 1024) /* 64MB -- more? */
#endif
#endif
#ifdef WITH_MEMORY_LIMITS
#define MAX_ARENAS (SMALL_MEMORY_LIMIT/ARENA_SIZE)
#endif
Python申请内存时,最基本的操作单元并不是arena,而是pool
pool的三种状态:used,full,empty
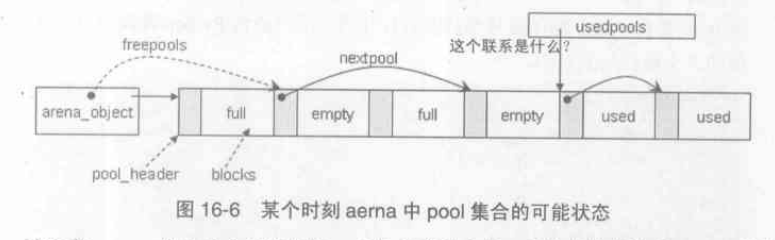
//usedpools结构
[obmalloc.c]
typedef uchar block;
#define PTA(x) ((poolp)((uchar* )&usedpools[2 * (x)]) - 2 * sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
static poolp usedpools[2 * (NB_SMALL_SIZE_CLASSES + 7)/8 * 8] = {
PT(0),PT(1),PT(2),PT(3),PT(4),PT(5),PT(6),PT(7)
#if NB_SMALL_SIZE_CLASSES > 8
, PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
...
#endif
}
//NB_SMALL_SIZE_CLASSES
[obmalloc.c]
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
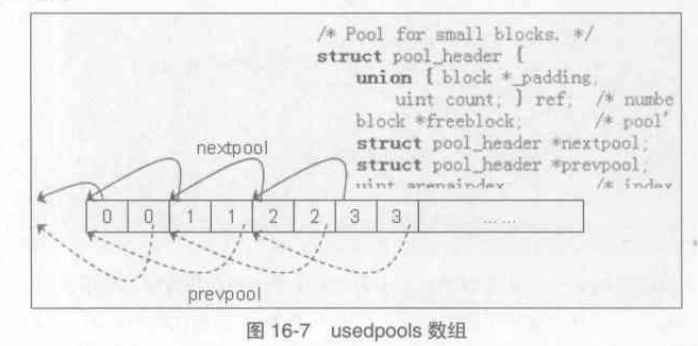
[obmalloc.c]
void* PyObject_Malloc(size_t nbytes){
block* bp;
poolp pool;
poolp next;
uint size;
if((nbytes - 1) < SMALL_REQUEST_THRESHOLD){
LOCK();
//获得size class index
size = (uint )(nbytes - 1) >> ALIGNMENT_SHIFT
pool = usedpools[size + size];
//usedpools中有可用的pool
if(pool != pool->nextpool){
....//usedpools中有可用的pool
}
...//usedpools中无可用pool,尝试获取empty状态pool
}
}
pool 的初始化
!!!!!!arena没有size class的属性,而pool才有
[obmalloc.c]
void* PyObject_Malloc(size_t nbytes){
block* bp;
poolp pool;
poolp next;
uint size;
if((nbytes - 1) < SMALL_REQUEST_THRESHOLD){
LOCK();
size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
pool = usedpools[size + size];
if(pool != pool->nextpool){
...//usedpools中有可用的pool
}
//usedpools中无可用pool,尝试获取empty状态pool
//如果usable_arenas链表为空,则创建链表
if(usable_arenas == NULL){
//申请新的arena_object,并放入usable_arenas链表
usable_arenas = new_arena();
usable_arenas->nextarena = usable_arenas->prevarena = NULL;
}
//从usable_arenas链表中第一个arena的freepools中抽取一个可用的pool
pool = usable_arenas->freepools;
if(pool != NULL){
usable_arenas->freepools = pool->nextpool;
//调整usable_arenas链表中第一个arena中的可用pool数量
//如果调整后数量为0,则将该arena从usable_arenas链表中摘除
--usable_arenas->nfreepools;
if(usable_arenas->nfreepools == 0){
usable_arenas = usable_arenas->nextarena;
if(usable_arenas != NULL){
usable_arenas->prevarena = NULL;
}
}
init pool:
...
}
}
}
初始化之一
[obmalloc.c]
#define ROUNDUP(x) (((x) + ALIGNMENT_MASK) & ~ALIGNMENT_MASK)
#define POOL_OVERHEAD ROUNDUP(sizeof(struct pool_header));
void *PyObject_Malloc(size_t nbytes){
...
init_pool:
//将pool放入usedpools中
next = usedpools[size + size]; /* == prev */
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
// pool在之前就具有正确的size结构,直接返回pool中的一个block
//只有当一个pool从empty状态重新转为used状态之后,由于这时szidx还是其转为empty状态之前的szidx,所有才有可能执行
if(pool->szidx == size){
bp = pool->freeblock;
pool->freeblock = *(block **)bp;
UNLOCK();
return (void *)bp;
}
//初始化pool header,将freeblock指向第二个block,返回第一个block
pool->szidx = size;
size = INDEX2SIZE(size);
bp = (block *)pool + POOL_OVERHEAD;
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
UNLOCK();
return (void *)bp;
...
}
empty状态转换到used状态
[obmalloc.c]
...
pool = usable_arenas->freepools;
if(pool != NULL){
usable_arenas->freepools = pool->nextpool;
...//调整usable_arenas->nfreepools和usable_arenas自身
[init_pool]
}
初始化之二
[obmalloc.c]
#define DUMMY_SIZE_IDX 0xffff /* size class of newly cached pools */
void* PyObject_Malloc(size_t nbytes){
block* bp;
poolp pool;
poolp next;
uint size;
...
//从arena中取出一个新的pool
pool = (poolp)usable_arenas->pool_address;
pool->arenaindex = usable_arenas - arenas;
pool->szidx = DUMMY_SIZE_IDX;
usable_arenas->pool_address += POOL_SIZE;
--usable_arenas->nfreepools;
if(usable_arenas->nfreepools == 0){
/* Unlink the arena : it is completely allocated */
usable_arenas = usable_arenas->nextarena;
if(usable_arenas != NULL){
usable_arenas->prevarena = NULL;
}
}
goto init_pool:
...
//判断一个block是否在某一个pool中
[obmalloc.c]
//P为指向一个block的指针,pool为指向一个pool的指针
int Py_ADDRESS_IN_RANGE(void* P, poolp pool){
return pool->arenaindex < maxarenas &&
(uptr)P - arenas[pool->arenaindex].address < (uptr)ARENA_SIZE && arenas[pool->arenaindex].address != 0;
}
//PyObject_Malloc的总体结构
[obmalloc.c]
void* PyObject_Malloc(size_t nbytes){
block* bp;
poolp pool;
poolp next;
uint size;
//如果申请的内存小于SMALL_REQUEST_THRESHOLD,使用Python的小块内存的内存池
//否则转向malloc
if((nbytes - 1) < SMALL_REQUEST_THRESHOLD){
//根据申请内存的大小获得对应的size class index
size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
pool = usedpools[size + size];
//如果usedpools中可用的pool,使用这个pool来分配block
if(pool != pool->next){
...//在pool中分配block
//分配结束后,如果pool中的block被分配了,将pool从usedpools中摘除(其实就是在双链表中去掉节点)
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
return (void *)bp;
}
//usedpools中没有可用的pool,从usable_arenas中获取pool
if(usable_arenas == NULL){
//usable_arenas中没有“可用”的arena,开始申请arena
usable_arenas = new_arena();
usable_arenas->nextarena = usable_arenas->prevarena = NULL;
}
//从usable_arenas中的第一个arena中获取一个pool
pool = usable_arenas->freepools;
if(pool != NULL){
init_pool:
//获取pool成功,进行init pool的动作,将pool放入used_pools中,
//并返回分配得到的block
......
}
//获取pool失败,对arena中的pool集合进行初始化
//然后转入goto到init pool的动作处,初始化一个特定的pool
...
goto init_pool;
}
redirect:
//如果申请的内存不小于SMALL_REQUEST_THRESHOLD,使用malloc
if(nbytes == 0)
nbytes = 1;
return (void *)malloc(nbytes);
}
block的释放
释放一个block后,pool的状态有两种转变情况: 1.used状态转变为empty状态 2.full状态转变为used状态 3.used仍然处于used状态
//used->used
[obmalloc.c]
void PyObject_Free(void *p){
poolp pool;
block* lastfree;
poolp next, prev;
uint size;
pool = POOL_ADDR(p);
if(Py_ADDRESS_IN_RANGE(p,pool)){
//设置离散自由block链表
*(block **)p = lastfree = pool->freeblock;
pool->freeblock = (block *)p;
if(lastfree){ //lastfree有效,表明当前pool不是处于full状态
if(--pool->ref.count != 0){ // pool不需要转换为empty状态
return;
}
...
}
...
}
//待释放的内存在PyObject_Malloc中是通过malloc获得的
//所以要归还给系统
free(p);
}
//full->used
[obmalloc.c]
void PyObject_Free(void *p){
poolp pool;
block *lastfree;
poolp next,prev;
uint size;
pool = POOL_ADDR(p);
if(Py_ADDRESS_IN_RANGE(p,pool)){
......
//当前pool处于full状态,在释放一块block后,需将其转换为used状态,并重新链入usedpools的头部
//链入usedpool头部
--pool->ref.count;
size = pool->szidx;
next = usedpools[size + size];
prev = next->prevpool;
pool->nextpool = next;
pool->prevpool = prev;
next->prevpool = pool;
prev->nextpool = pool;
return;
}
...
}
//used->empty
[obmalloc.c]
void PyObject_Free(void *p){
poolp pool;
block* lastfree;
poolp next, prev;
uint size;
pool = POOL_ADDR(p);
if(Py_ADDRESS_IN_RANGE(p,pool)){
//设置离散自由block链表
*(block **)p = lastfree = pool->freeblock;
pool->freeblock = (block *)p;
if(lastfree){
struct arena_object* ao;
uint nf; //ao->nfreepools
if(--pool->ref.count != 0){
return;
}
//将pool放入freepools维护的链表中
ao = &arenas[pool->arenaindex];
pool->nextpool = ao->freepools;
ao->freepools = pool;
nf = ++ao->nfreepools;
...
}
...
}
}
对arena的处理分为了4种情况
如果arena中所有pool都是empty的,释放pool集合占用的内存
[obmalloc.c]
void PyObject_Free(void *p){
poolp pool;
block* lastfree;
poolp next,prev;
uint size;
pool = POOL_ADDR(p);
struct arena_object* ao;
uint nf; //ao->nfreepools
...
//将pool放入freepools维护的链表中
ao = &arenas[pool->arenaindex];
pool->nextpool = ao->freepools;
ao->freepools = pool;
nf = ++ao->nfreepools;
if(nf == ao->ntotalpools ){
//调整usable_arenas链表
if(ao->prevarena == NULL){
usable_arenas = ao->nextarena;
}else{
ao->prevarena->nextarena = ao->nextarena;
}
if(ao->nextarena != NULL){
ao->nextarena->prevarena = ao->prevarena;
}
//调整unused_arena_objects链表
ao->nextarena = unused_arena_objects;
unused_arena_objects = ao;
//释放内存
free((void *)ao->address);
//设置address,将arena的状态转换为“未使用”
ao->address = 0;
--narenas_currently_allocated;
}
....
}

内存池全景
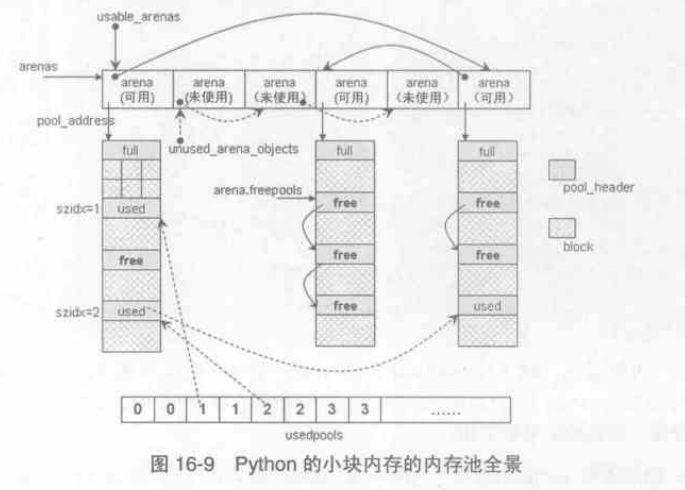
c.循环引用的垃圾收集
引用计数与垃圾收集
python大量使用的面向特定对象的对象内存池机制正是为了竭力弥补引用计数机制的软肋
python中引入了主流垃圾收集技术中的*标记-清除 和 分代收集*来填补其内存管理机制中最后也是最致命的漏洞
三色标记模型
垃圾收集机制的两个阶段:垃圾检测和垃圾回收
标记-清除方法的两个阶段

在垃圾收集动作被激活之前,系统中所分配的所有对象和对象之间的引用组成了一张有向图,其中对象是图中的节点,对象间的引用是图的边
d.Python中的垃圾收集
解决循环引用只需要去检查container对象(list,dict),而不用去关心PyIntObject...
python采用了一个双向链表,所有的container对象在创建之后,都会被插入到这个链表中
可收集对象链表
[objimpl.h]
typedef union _gc_head{
struct {
union _gc_head* gc_next;
union _gc_head* gc_prev;
int gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
[gcmodule.c]
PyObject* _PyObject_GC_New(PyTypeObject *tp){
PyObject* op = _PyObject_GC_Malloc(_PyObject_SIZE(tp));
if(op != NULL)
op = PyObject_INIT(op,tp);
return op;
}
#define _PyGC_REFS_UNTRACKED (-2)
#define GC_UNTRACKED _PyGC_REFS_UNTRACKED
PyObject* _PyObject_GC_Malloc(size_t basicsize){
PyObject* op;
// 为对象本身及PyGC_Head申请内存
PyGC_Head* g = PyObject_MALLOC(sizeof(PyGC_Head) + basicsize);
g->gc.gc_refs = GC_UNTRACKED;
generations[0].count++; /* number of allocated GC objects */
if(generations[0].count > generations[0].threshold &&
enabled &&
generations[0].threshold &&
!collecting &&
!PyErr_Occured()){
collecting = 1;
collect_generations();
collecting = 0;
}
op = FROM_GC(g);
return op;
}

//从PyGC_Head地址转换为PyObject_HEAD地址的算法
[gcmodule.c]
/* Get an object's GC head */
#define AS_GC(o) ((PyGC_HEAD *)(o) -1)
/* Get the object given the GC head */
#define FROM_GC(g) ((PyObject *)(((PyGC_HEAD *)g) + 1))
[objimpl.h]
#define _Py_AS_GC(o) ((PyGC_HEAD *)(o) - 1)
//将container对象链入链表的时间点
[dictobject.c]
PyObject* PyDict_New(void){
register dictobject *mp;
...
mp = PyObject_GC_New(dictobject,&PyDict_Type);
...
_PyObject_GC_TRACK(mp); //链入链表
return (PyObject *)mp;
}
[objimpl.h]
#define _PyObject_GC_TRACK(o) do{
PyGC_Head* g = _Py_AS_GC(o;)
if(g->gc.gc_refs != _PyGC_REFS_UNTRACKED)
Py_FataError("GC object already tracked");
g->gc.gc_refs = _PyGC_REFS_REACHABLE;
g->gc.gc_next = _PyGC_generation0;
g->gc.gc_prev = _PyGC_generation0->gc.gc_prev;
g->gc.gc_prev->gc.gc_next = g;
_PyGC_generation0->gc.gc_prev = g;
}while (0);
[objimpl.h]
#define _PyObject_GC_UNTRACK(o) do{
PyGC_Head* g = _Py_AS_GC(o;)
assert(g->gc.gc_refs != _PyGC_REFS_UNTRACKED);
g->gc.gc_refs = _PyGC_REFS_UNTRACKED;
g->gc.gc_prev->gc.gc_next = g->gc.gc_next;
g->gc.gc_next->gc.gc_prev = g->gc.gc_prev;
g->gc.gc_next = NULL;
}while (0);
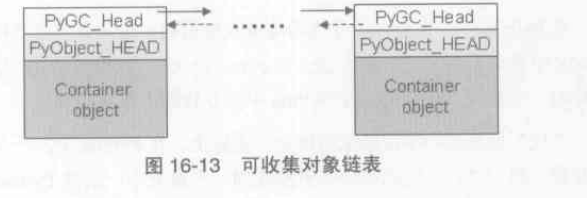
分代的垃圾收集
规律:一定比例的内存块的生存周期都比较短,通常是几百万条机器指令的时间,而剩下的内存块,其生存周期会比较长,甚至会从程序开始一直持续到程序结束
核心:空间换时间的分代技术, java的老底
手法:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就称为一个“代”,垃圾收集的频率随着”代“的存活时间的增大而减小,如果一个对象经过的垃圾收集次数越多,其存活时间就越长
python一共有三代,_PyGC_generation0是python内部维护的一个指针,指向的是Python中第0代的内存块集合
[gcmodule.c]
struct gc_generation{
PyGC_Head head;
int threshold; /* collection threshold */
int count; /* count of allocations or collections of younger generations */
};
[gcmodule.c]
#define NUM_GENERATIONS 3
#define GEN_HEAD(n) (&generations[n].head)
/* linked lists of container objects */
static struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{{GEN_HEAD(0),GEN_HEAD(0),0}},700,0},
{{{GEN_HEAD(1),GEN_HEAD(1),0}},10, 0},
{{{GEN_HEAD(2),GEN_HEAD(2),0}},10, 0},
};
PyGC_Head *_PyGC_generation0 = GEN_HEAD(0);
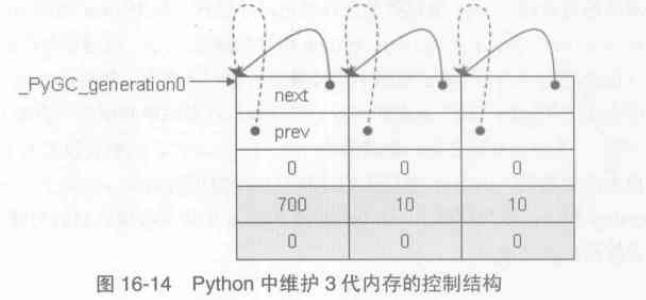
//第0代内存链表可容纳700个container,一旦超过就会触发垃圾收集机制
[gcmodule.c]
static Py_ssize_t collect_generations(void){
int i;
Py_ssize_t n = 0;
/* 如果count大于threshold,那么回收这一代以及更年轻的一代 */
for(i = NUM_GENERATIONS - 1; i >= 0; i--){
if(generations[i].count > generations[i].threshold){
n = collect(i);
break;
}
}
return n;
}
Python中的标记-清除方法
\\将比其“年轻”的所有代的内存链表整个链接到第1代内存链表之后
[gcmodule.c]
static void gc_list_init(PyGC_Head* list){
list->gc.gc_prev = list;
list->gc.gc_next = list;
}
static void gc_list_merge(PyGC_Head* from, PyGC_Head* to){
PyGC_Head* tail;
if(!gc_list_is_empty(from)){
tail = to->gc.gc_prev;
tail->gc.gc_next = from->gc.gc_next;
tail->gc.gc_next->gc.gc_prev = tail;
to->gc.gc_prev = from->gc.gc_prev;
to->gc.gc_prev->gc.gc_next = to;
}
gc_list_init(from);
}
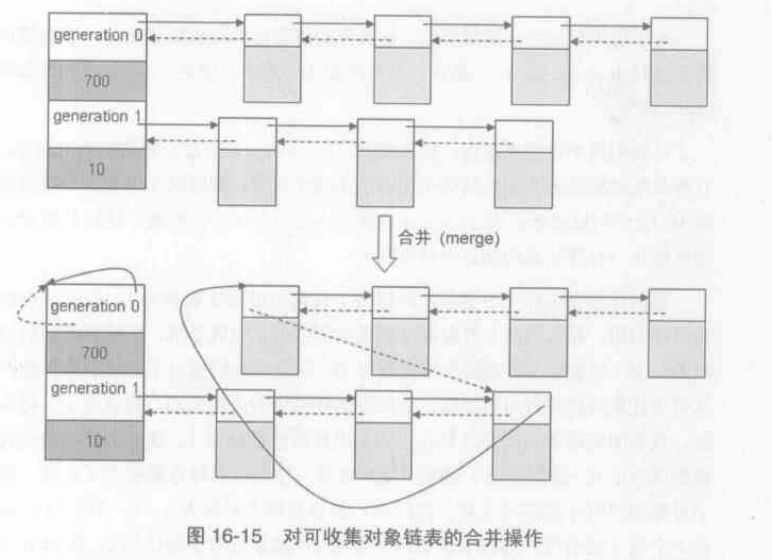
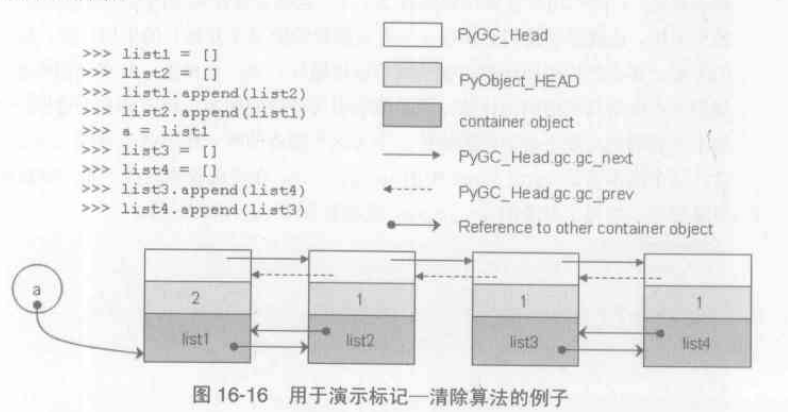
寻找Root Object集合
root object是不能被删除的对象,有可收集对象链表外部的某个引用在引用这个对象
//gc.gc_ref为ob_refcnt值的副本
[gcmodule.c]
static void update_refs(PyGC_Head* containers){
PyGC_Head* gc = containers->gc.gc_next;
for(;gc != containers; gc = gc->gc.gc_next){
assert(gc->gc.gc_refs == GC_REACHABLE);
gc->gc.gc_refs = FROM_GC(gc)->ob_refcnt;
}
}
//将循环引用从引用中摘除
[gcmodule.c]
static void subtract_refs(PyGC_Head* containers){
traverseproc traverse;
PyGC_Head* gc = containers->gc.gc_next;
for(;gc != containers; gc = gc->gc.gc_next){
traverse = FROM_GC(gc)->ob_type->tp_traverse;
(void)traverse(FROM_GC(gc),(visitproc)visit_decref,NULL);
}
}
以PyDictObject对象所定义的traverse操作为例
[object.h]
typedef int (*visitproc)(PyObject *, void *);
typedef int (*traverseproc)(PyObject *, visitproc, void *);
[dictobject.c]
PyTypeObject PyDict_Type = {
...
(traverseproc)dict_traverse, /* tp_traverse */
...
};
static int dict_traverse(PyObject* op, visitproc visit, void* arg){
int i = 0, err;
PyObject* pk;
PyObject* pv;
while (PyDict_Next(op,&i,&pk,&pv)) {
visit(pk,arg);
visit(pv,arg);
}
}
[gcmodule.c]
static int visit_decref(PyObject* op, void* data){
//PyObject_IS_GC判断op指向的对象是不是被垃圾收集监控的
//通常在container对象的type对象中有Py_TPFLAGS_HAVE_GC符号
//标识container对象是被垃圾收集监控的
if(PyObject_IS_GC(op)){
PyGC_Head* gc = AS_GC(op);
if(gc->gc.gc_refs > 0)
gc->gc.gc_refs--;
}
return 0;
}
subtract_refs之后,不为0的就是root object
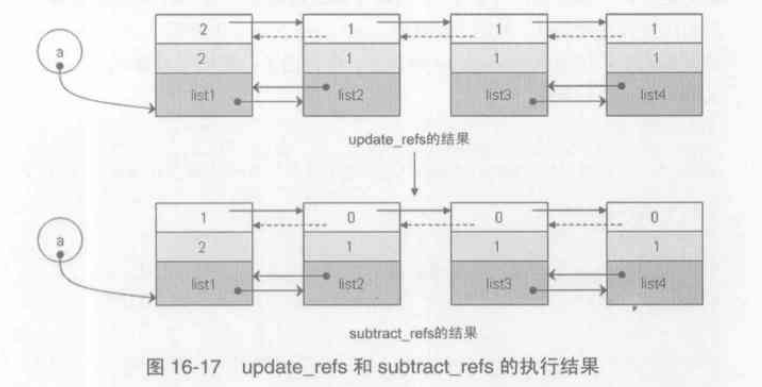
垃圾标记
root object不可回收,分成两条链root链和unreachable链
[gcmodule.c]
static void move_unreachable(PyGC_Head* young, PyGC_Head* unreachable){
PyGC_Head* gc = young->gc.gc_next;
while(gc != young){
PyGC_Head* next;
//对于root object, 设置其gc_refs为GC_REACHABLE标志
if(gc->gc_refs){
PyObject* op = FROM_GC(gc);
traverseproc traverse = op->ob_type->tp_traverse;
gc->gc.gc_refs = GC_REACHABLE;
(void)traverse(op,(visitproc)visit_reachable,(void *)young);
next = gc->gc.gc_next;
}
//对于非root对象,移到unreachable链表中
//并标记为GC_TENTATIVELY_UNREACHABLE
else{
next = gc->gc.gc_next;
gc_list_move(gc,unreachable);
gc->gc.gc_refs = GC_TENTATIVELY_UNREACHABLE;
}
gc = next;
}
}
static int visit_reachable(PyObject* op, PyGC_Head* reachable){
if(PyObject_IS_GC(op)){
PyGC_Head* gc = AS_GC(op);
const int gc_refs = gc->gc.refs;
//对于还没处理的对象,恢复其gc_refs
if(gc_refs == 0){
gc->gc.gc_refs = 1;
}
//对于已经被挪到unreachable链表中的对象,将其再次挪到原来的链表
else if(gc_refs == GC_TENTATIVELY_UNREACHABLE){
gc_list_move(gc,reachable);
gc->gc.gc_refs = 1;
}
else{
assert(gc_refs > 0 || gc_refs == GC_REACHABLE || gc_refs == GC_UNTRACKED);
}
}
return 0;
}
特殊的container对象,即从类对象实例化得到的实例对象,有一个特殊方法"__del__",被称为finalizer,假如对象B在finalizer中调用对象A的某个操作,Python必须先回收B,再回收A,但python无法保证回收顺序,采取的方法是:!!!将unreachable链表中的拥有finalizer的PyInstanceObject对象统统都移到一个名为garbage的PyListObject对象
垃圾回收
将unreachable链表中的每一个对象的ob_refcnt变为0,引发对象的销毁
[gcmodule.c]
static int gc_list_is_empty(PyGC_Head* list){
return (list->gc.gc_next == list);
}
static void delete_garbage(PyGC_Head* collectable, PyGC_Head* old){ //old为reachable链表
inquiry clear;
while(!gc_list_is_empty(collectable)){
PyGC_Head* gc = collectable->gc.gc_next;
PyObject* op = FROM_GC(gc);
if((clear = op->ob_type->tp_clear) != NULL){
Py_INCREF(op);
clear(op);
Py_DECREF(op);
}
if(collectable->gc.gc_next == gc){
/* object is still alive, move it, it may die later */
gc_list_move(gc,old);
gc->gc.gc_refs = GC_REACHABLE;
}
}
}
//会调用container对象的类型对象中的tp_clear操作,操作会调整container对象中每个引用所用的对象的引用计数值,从而完成打破循环的最终目标
//以list为例子
[listobject.c]
static int list_clear(PyListObject* a){
int i;
PyObject** item = a->ob_item;
if(item != NULL){
i = a->ob_size;
a->ob_size = 0;
a->ob_item = NULL;
a->allocated = 0;
while(--i >= 0){
Py_XDECREF(item[i]);
}
PyMem_FREE(item);
}
return 0;
}
[listobject.c]
static void list_dealloc(PyListObject* op){
int i;
PyObject_GC_UnTrack(op);
if(op->ob_item != NULL){
i = op->ob_size;
while(--i >= 0){
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
...
}
垃圾收集全景
[gcmodule.c]
static long collect(int generation){
int i;
long m = 0; /* # objects collected */
long n = 0; /* # unreachable objects that couldn't be collected */
PyGC_Head* young; /* the generation we are examining */
PyGC_Head* old; /* next older generation */
PyGC_Head unreachable; /* non-problematic unreachable trash */
PyGC_Head finalizers; /* objects with, &reachable from, __del__ */
PyGC_Head* gc;
if(delstr == NULL){
delstr = PyString_InternFromString("__del__");
if(delstr == NULL)
Py_FataError("gc couldn't allocate \"__del__\"");
}
/* update collection and allocation counters */
if(generation + 1 < NUM_GENERATIONS)
generations[generation + 1].count += 1;
for(i = 0;i < generation; i++)
generations[i].count = 0;
/* merge younger generations with one we are currently collecting */
for(i = 0; i < generation; i++){
gc_list_merge(GEN_HEAD(i),GEN_HEAD(generation));
}
/* handy references */
young = GEN_HEAD(generation);
if(generation < NUM_GENERATIONS - 1)
old = GEN_HEAD(generation + 1);
else
old = young;
//在待处理链表上进行打破循环的模拟,寻找root object
update_refs(young);
subtract_refs(young);
//将待处理链表中的unreachable object转移到unreachable链表中
//处理完成后,当前“代”中只剩下了reachable object了
gc_list_init(&unreachable);
move_unreachable(young, &unreachable);
//如果可能将当前"代"中的reachable object合并到更老的”代”中
if(young != old)
gc_list_merge(young,old);
//对于unreachable链表中的对象,如果其带有__del__函数,则不能安全回收
//需要将这些对象收集到finalizers链表中,因此,这些对象引用的对象也不能
//回收,也需要放入finalizers链表中
gc_list_init(&finalizers);
move_finalizer(&unreachable,&finalizers);
move_finalizer_reachable(&finalizers);
//处理若引用(weakref),如果可能,调用弱引用中注册的callback操作
handle_weakrefs(&unreachable,old);
//对unreachable链表上的对象进行垃圾回收操作
delete_garbage(&unreachable,old);
//将含有__del__操作的实例对象收集到python内部维护的名为garbage的链表中
//同时将finalizers链表中所有对象加入到old链表中
(void)handle_finalizers(&finalizers,old);
...
}
//PyFunctionObject对象的正常销毁
[funcobject.c]
static void fun_dealloc(PyFunctionObject* op){
_PyObject_GC_UNTRACK(op);
...
PyObject_GC_Del(op);
}
[gcmodule.c]
void PyObject_GC_Del(void* op){
PyGC_Head* g = AS_GC(g);
if(IS_TRACKED(op))
gc_list_merge(g);
if(generation[0].count > 0){
generations[0].count--;
}
PyObject_FREE(g); //最终调用PyObject_FREE
}
总之,python的垃圾收集机制单纯是为了服务循环引用
Python中的gc模块
[gc1.py]
import gc
class A(object):
pass
class B(object):
pass
gc.set_debug(gc.DEBUG_STATS | gc.DEBUG_LEAK)
a = A()
b = B()
del a
del b
gc.collect()
[gc2.py]
import gc
class A(object):
pass
class B(object):
pass
gc.set_debug(gc.DEBUG_STATS | gc.DEBUG_LEAK)
a = A()
b = B()
a.b = b
b.a = a
del a
del b
gc.collect()
[gc3.py]
import gc
class A(object):
def __del__(self):
pass
class B(object):
def __del__(self):
pass
gc.set_debug(gc.DEBUG_STATS | gc.DEBUG_LEAK)
a = A()
b = B()
a.b = b
b.a = a
del a
del b
gc.collect()